
[개념정리] Convolutional Neural Network
Basics
이미지 처리
이미지를 sequence 형태로 처리하면 단순한 문제는 어느 정도 해결할 수 있으나 좋은 성능을 기대하기는 어렵다. 이미지 내에 같은 객체가 있다고 하더라도 위치나 크기가 조금만 달라져도 벡터는 크게 변화할 수 있기 때문이다. 따라서 필터(또는 Kernel)를 이용해 이미지의 일부분을 하나씩 살펴 보면서 연산하는 것이 CNN의 기본 개념이다.
합성곱 연산(Convolution operation
합성곱층은 합성곱 연산을 통해서 이미지의 특징을 추출하는 역할을 한다. 우선, 합성곱 연산에 대해서 이해해봅시다. n x m 커널 또는 필터 행렬을 통해 겹쳐지는 부분의 각 이미지와 커널의 원소의 값을 곱해서 모두 더한 값을 출력으로 하는 것을 말한다. 이때, 이미지의 가장 왼쪽 위부터 가장 오른쪽까지 순차적으로 연산한다. 합성곱 연산을 통해 나온 결과를 특성 맵(feature map)이라고 한다.
풀링(Pooling)
일반적으로 합성곱 층(합성곱 연산 + 활성화 함수) 다음에는 풀링 층을 추가하는 것이 일반적이다. 풀링 층에서는 특성 맵을 다운샘플링하여 특성 맵의 크기를 줄이는 풀링 연산이 이루어진다. 풀링 연산에는 일반적으로 최대 풀링(max pooling)과 평균 풀링(average pooling)이 사용된다.
AlexNet
AlexNet은 2012년에 ILSVRC에서 우승한 대표적인 CNN 모델이며 제프리 힌튼 교수 그룹이 만든 네트워크이다. 논문은 2012년 NeurIPS에 게제되었다. 2개의 GPU로 병렬연산을 수행하기 위해서 병렬적인 구조로 설계되었다는 점이 가장 큰 변화이다.
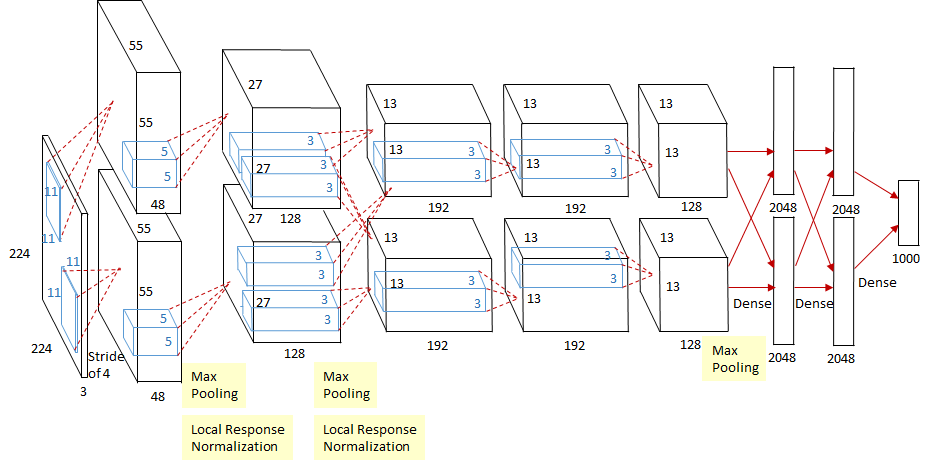
AlexNet은 8개의 레이어로 구성되어 있다. 5개의 컨볼루션 레이어와 3개의 full-connected 레이어로 구성되어 있다. 두번째, 네번째, 다섯번째 컨볼루션 레이어들은 전 단계의 같은 채널의 특성맵들과만 연결되어 있는 반면, 세번째 컨볼루션 레이어는 전 단계의 두 채널의 특성맵들과 모두 연결되어 있다는 것을 집고 넘어가자.
ResNet
ResNet은 ILSVRC 2015에서 우승한 모델이며, 이후 중요한 개념으로 자리잡은 Residual Block을 제안한 모델이다. ResNet은 152층까지 layer를 쌓으며 처음으로 Human Error를 능가하는 3.57%의 top5 error 를 보였다. ResNet에서 제시하는 Residual Learning이라는 개념은 이후 많은 모델들에서 응용되었으며, 아직까지도 많은 사람들이 성능도 좋고, 구현도 편하고 단순하다는 점 때문에 ResNet을 유용하게 사용하고 있다.
“Deep” 네트워크
Inception과 VGG가 보다 ‘깊은’ 네트워크임을 강조하면서 ILSVRC에서 좋은 성적을 거두게 되었지만 사람들은 과연 네트워크가 깊어지는 것 만으로 성능을 향상시킬 수 있을까? 라는 의문을 가지게 되었다. “plain” convolutional neural network에서 Layer를 무작정 늘렸을 때 성능이 오히려 떨어졌기 때문이다. Training 에서도, Test 에서도 성능이 좋지 않았기 때문에 우리는 이것이 Overfitting 때문이 아님을 알 수 있다. 우선 직관적으로 우리는 Gradient vanishing / explosion이 발생할 수 있음을 알 수 있다. 이것 외에도 우리는 Degradation Problem이라고 부르는, layer가 어느정도 이상으로 깊어지면 오히려 성능이 안좋아지는 현상이 벌어짐을 알 수 있다. 이 현상의 원인을 어떤 사람들은 layer가 깊어졌을 때 Optimization이 제대로 되지 않아서 라고 추측했는데. ResNet은 네트워크의 개선을 통해서 이 문제를 해결했다.
Residual Block & Skip Connection
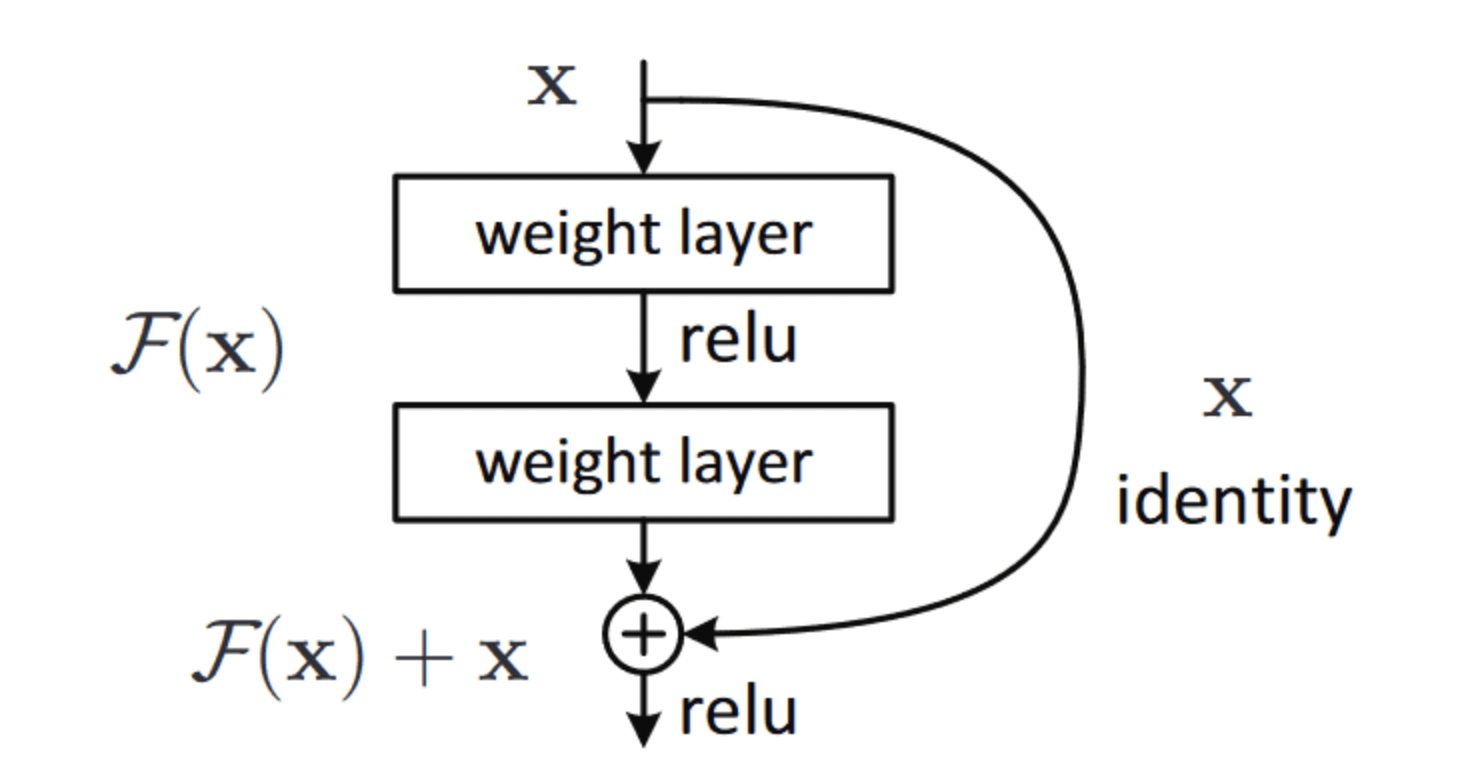
Skip Connection이란 여러 레이어를 건너 뛰어 이전 정보를 더하는 것을 의미하며, 이 과정을 하나로 묶어 만든 것이 Residual Block이다. 기본적으로 2개, 3개의 Conv layer를 뛰어넘어 더하는 방식을 사용하며 ResNet은 이러한 Residual Block을 Stack한 구조를 갖는다.
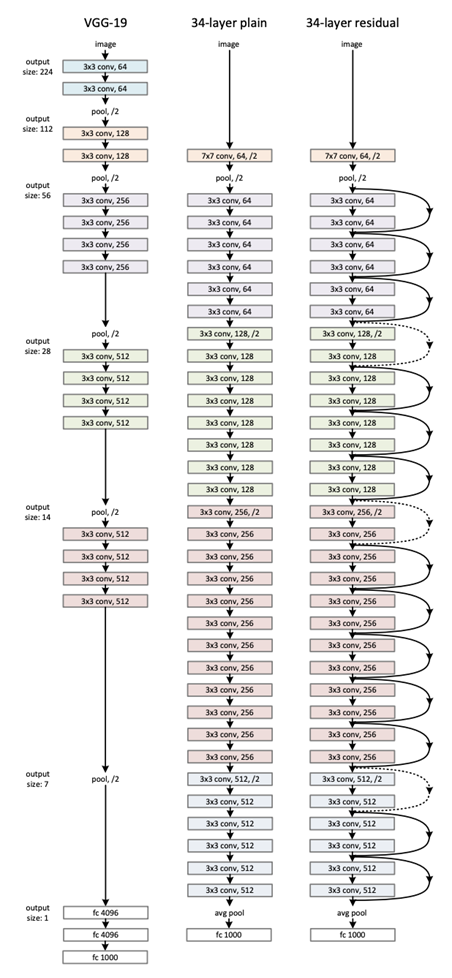
ResNet이 잘 되는 이유
원 논문에서는 자신들이 어떤 이론을 바탕으로 결과를 도출했다기 보다는 경험적으로 residual block을 쓰니 결과가 좋게 나왔다고 한다. ResNet이 왜 잘 동작하는지 설명하려는 많은 노력이 있었고, 아직까지도 많은 사람들이 연구하고 있다. 그 중에서 한 가지는 바로 Residual Net이 만들어내는 모델을 이용하는 것은 Optimal depth에서의 모델을 사용하는 것과 비슷하다는 가설이다.
우리는 쉽게 Optimal depth를 알 수가 없다. 20층이 Optimal인지, 30층이 optimal인지, 아무도 모른다. 하지만, degradation problem은 알 수 없는 optimal depth를 넘어가면 바로 일어난다.
ResNet은 엄청나게 깊은 네트워크를 만들어주고, Optimal depth에서의 값을 바로 Output으로 보낼수 있다. ResNet은 Skip connection이 존재하기 때문에 Main path에서 Optimal depth이후의 Weight와 Bias가 전부 0에 수렴하도록 학습된다면 Optimal depth에서의 Output이 바로 Classification으로 넘어갈 수 있다. 즉 Optimal depth이후의 block은 모두 빈깡통이라는 것이다.
예를 들어 27층이 Optimal depth인데 ResNet 50에서 학습을 한다면, 28층부터 Classification 전까지의 weight와 bias를 전부 0으로 만들면 27층에서의 output이 바로 Classification에서 이용되고, 이는 Optimal depth의 네트워크를 그대로 사용하는것과 같다고 볼 수 있다.
Leave a comment