
[실험정리] TensorRT
General
- TensorRT는 학습된 딥러닝 모델을 최적화하여 NVIDIA GPU 상에서의 추론 속도를 수배 ~ 수십배 까지 향상시켜 딥러닝 서비스를 개선하는데 도움을 줄 수 있는 모델 최적화 엔진이다.
- 흔히들 우리가 접하는 Caffe, Pytorch, TensorFlow, PaddlePaddle 등의 딥러닝 프레임워크를 통해 짜여진 딥러닝 모델을 TensorRT를 통해 모델을 최적화하여 TESLA T4 , JETSON TX2, TESLA V100 등의 NVIDIA GPU 플랫폼에 아름답게 싣는 것이다.
- 또한, TensorRT는 NVIDIA GPU 연산에 적합한 최적화 기법들을 이용하여 모델을 최적화하는 Optimizer 와 다양한 GPU에서 모델 연산을 수행하는 Runtime Engine 을 포함한다.
- TensorRT는 대부분의 딥러닝 프레임워크에서 학습된 모델을 지원하며, 최적의 딥러닝 모델 가속화를 지원한다.
- TensorRT의 장점은 C++ 및 Python 을 API 레벨에서 지원하고 있기 때문에 GPU 프로그래밍인 CUDA 지식이 별로 없어도 딥러닝 분야의 개발자들이 쉽게 사용할 수 있다.
- 또한 GPU가 지원하는 활용 가능한 최적의 연산 자원을 자동으로 사용할 수 있도록 Runtime binary 를 빌드해주기 때문에 Latency 및 Throughput 을 쉽게 향상시킬 수 있고, 이를 통해 딥러닝 응용프로그램 및 서비스의 효율적인 실행이 가능하다.
- 또한 흔히들 알고있는 Convolution Layer, ReLU 등의 Layer 뿐 만 아니라 다양한 Layer 및 연산에 대하여 Customization 할 수 있는 방법론을 제공(다소 어려운 감이 있지만 …)하여 개발자들이 유연하게 TensorRT를 활용할 수 있도록 하고 있다.
Method
- Precision Calibration (ex. FP32 → FP16)
- Layer & Tensor Fusion
- Kernel Auto Tuning
- Dynamic Tensor Memory
- Multi-Stream Execution
Apply
- Pytorch → ONNX → TensorRT (바로 TensorRT로 갈 수 있는데 오닉스를 거쳐 가는게 좋음)
- NVIDIA 에서 Docker image 제공
yolov5 Convert
https://github.com/ultralytics/yolov5/issues/251
pip install onnx
pip install nvidia-pyindex
pip install nvidia-tensorrt
python path/to/export.py --device $ --weights yolov5s.pt --include onnx engine
yolov5 Inference Result
- Based on Custom weight - kasaV1
- TensorRT
- Speed: 0.2ms pre-process, 0.9ms inference, 0.5ms NMS per image at shape (1, 3, 640, 640) Frame rate: 649.0FPS
- ONNX
- Speed: 0.3ms pre-process, 25.3ms inference, 0.6ms NMS per image at shape (1, 3, 640, 640) Frame rate: 38.2FPS
- Original(Pytorch)
- Speed: 0.2ms pre-process, 2.6ms inference, 0.5ms NMS per image at shape (1, 3, 640, 640) Frame rate: 295.2FPS
- TensorRT
- Based on Benchmark weight - yolov5s
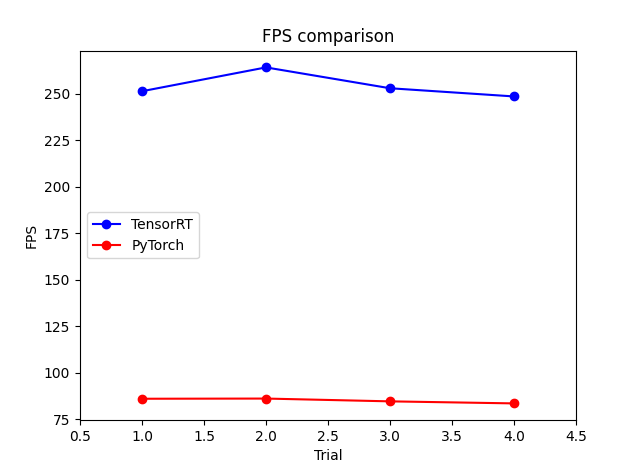
- TensorRT
- Speed: 1.8ms pre-process, 0.9ms inference, 1.3ms NMS per image at shape (1, 3, 640, 640) FPS: 251.3ps frame per sec
- Speed: 1.4ms pre-process, 0.9ms inference, 1.5ms NMS per image at shape (1, 3, 640, 640) FPS: 264.1ps frame per sec
- Speed: 1.7ms pre-process, 0.9ms inference, 1.3ms NMS per image at shape (1, 3, 640, 640) FPS: 252.9ps frame per sec
- Speed: 1.8ms pre-process, 0.9ms inference, 1.3ms NMS per image at shape (1, 3, 640, 640) FPS: 248.5ps frame per sec
- Original(Pytorch)
- Speed: 0.4ms pre-process, 10.3ms inference, 1.0ms NMS per image at shape (1, 3, 640, 640) Frame rate: 86.1FPS
- Speed: 0.4ms pre-process, 10.2ms inference, 1.0ms NMS per image at shape (1, 3, 640, 640) FPS: 86.2ps frame per sec
- Speed: 0.3ms pre-process, 10.5ms inference, 1.1ms NMS per image at shape (1, 3, 640, 640) FPS: 84.7ps frame per sec
- Speed: 0.4ms pre-process, 10.5ms inference, 1.0ms NMS per image at shape (1, 3, 640, 640) FPS: 83.6ps frame per sec
- TensorRT
- Inference Time Comparison → TensorRT mainly accelerate GPU inference
- Tested in RTX 3090 (w/ default threshold)
| | Trial 1 | Trial 2 | Trial 3 | Trial 4 | | — | — | — | — | — | | TensorRT | 0.9 ms | 0.9 ms | 0.9 ms | 0.9 ms | | Pytorch | 10.3 ms | 10.2 ms | 10.5 ms | 10.5 ms |
- Total Frame Rate Comparison (FPS)
- Tested in RTX 3090 (w/ default threshold)
Leave a comment