
[개념정리] Unsupervised Learning
Abstract
비지도 학습이란 레이블 없이 데이터의 특성을 파악하는 학습 방법이다. 즉, 모델에 정답을 알려주지 않기 때문에 레이블이 없는 데이터를 사용함으로써 데이터 수집, 가공 과정에서 발생하는 비용을 줄일 수 있다. 하지만 정답을 모르기 때문에 상대적으로 지도 학습에 비해 성능이 떨어질 수 있다. 대표적인 기법으로는 클러스터링, 오토인코더, GAN 등이 있다.
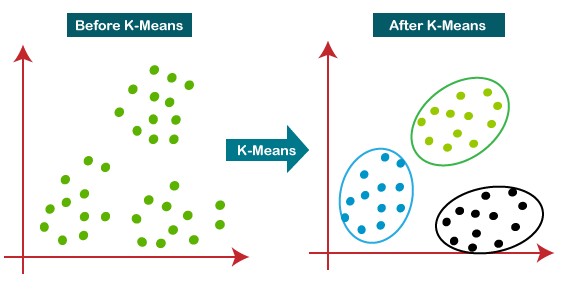
K-Means Clustering
클러스터링은 입력 데이터로부터 특성을 뽑아 유사 성질들을 군집화하는 비지도 학습이며 종류가 매우 다양하다. 정답이 없어 클러스터링 종류에 따라 군집을 다르게 할 수 있기 때문에 종류 선택과 각 알고리즘의 하이퍼 파라미터를 튜닝하는 과정이 중요하다.
K-Means 클러스터링은 각 클러스터의 평균을 기준으로 데이터들을 배치시키는 방법이다. 이때, 특정 거리 함수를 통해 각 클러스터의 중심(centeroid)와 데이터 간의 거리를 측정하고 가장 가까운 클러스터에 데이터를 할당한다. 이후 할당된 데이터의 평균을 구해 중심을 업데이트하고 다시 위 과정을 반복하여 수렴할 때까지 클러스터링을 수행한다.
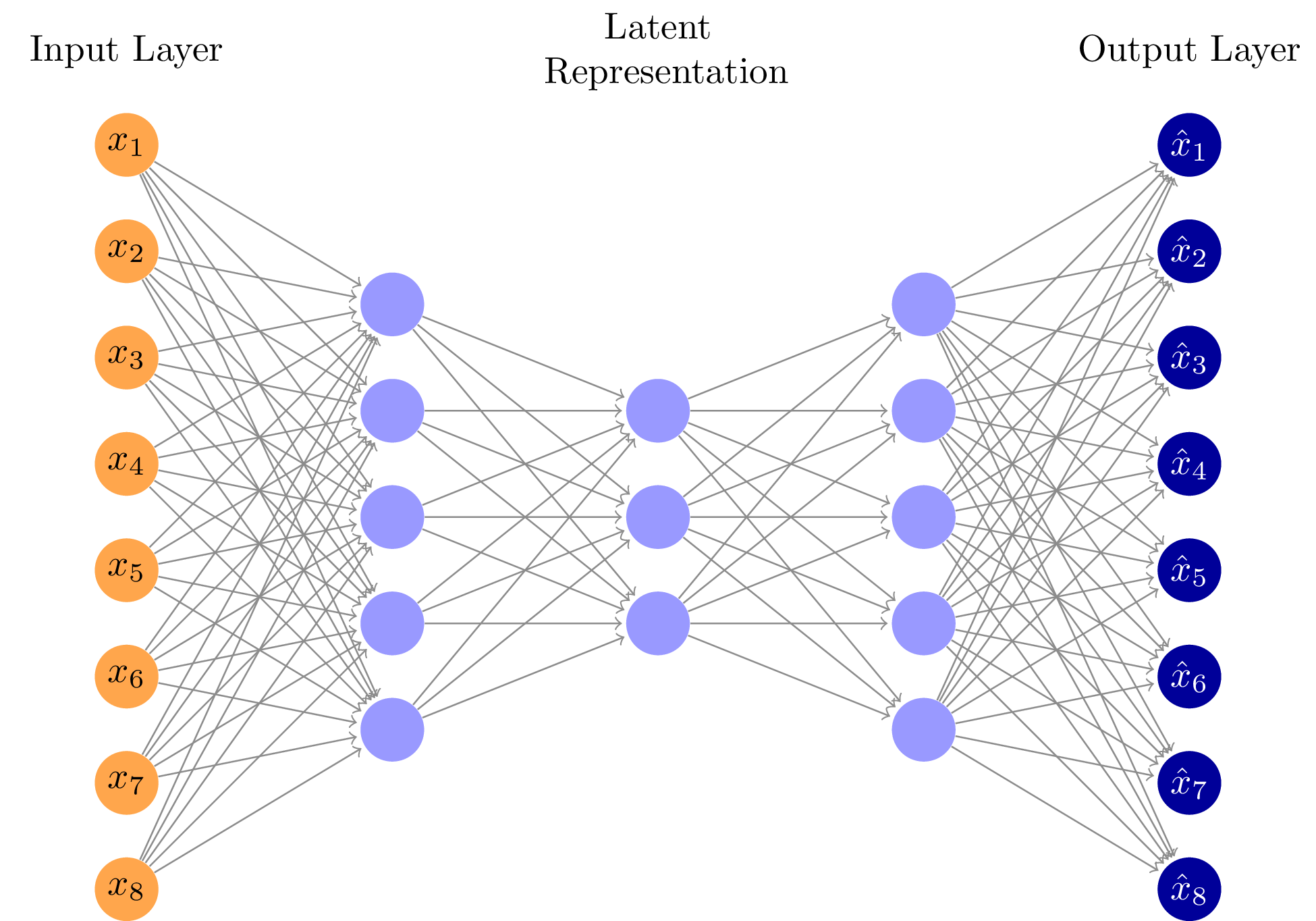
AutoEncoder
오토인코더는 입력 데이터를 압축하는 인코더 부분과 압출을 푸는 디코더 부분으로 구성되어 있다. 따라서 인코더를 통해 차원 축소가 된 잠재 변수(latent variable)를 가지고 별도로 계산을 할 수도 있고 디코더를 통해 입력값과 유사한 값을 생성할 수도 있다. 기본적으로 입력 x와 출력 x’을 이용하여 MSE를 정의하고 이를 기준으로 학습을 진행한다.
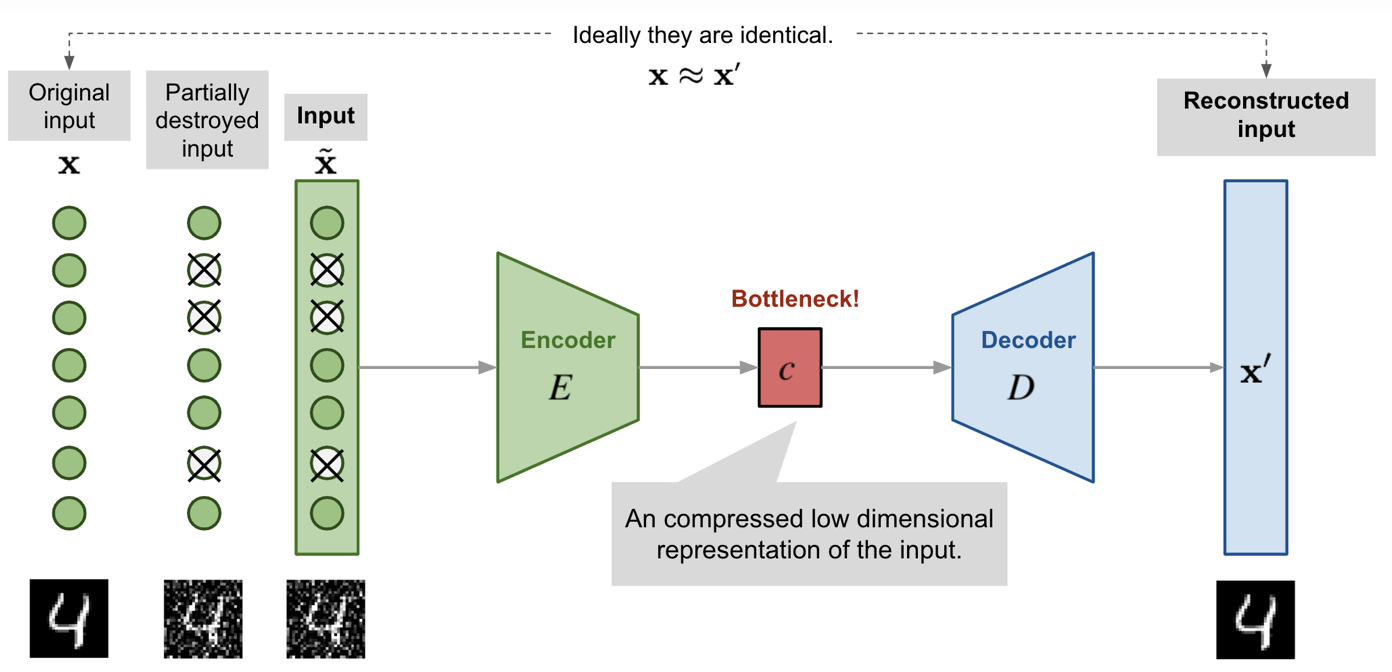
Denoising AutoEncoder
오토인코더의 기본적인 목적은 새로운 데이터를 만드는 것이다. 따라서 출력 데이터를 입력 데이터에 가까워지도록 학습한다면 기존의 데이터와 매우 유사하여 새로운 데이터를 만드는 의미가 무색해질 수 있다. 따라서 입력값에 과적합되지 않도록 입력값에 노이즈를 주입시키거나 신경망에 드롭아웃을 적용하여 출력 데이터를 생성하고 출력 데이터와 노이즈가 없는 원래 입력 데이터를 가지고 손실 함수를 계산한다. 따라서 노이즈가 있는 이미지를 가지고 노이즈가 없는 이미지와 유사한 데이터를 만드는 구조이기 때문에 이를 Denoising AutoEncoder라고 한다. 실제로 이미지 복원이나 노이즈 제거등에 이용된다.
Convolutional AutoEncoder
기본적인 오토인코더에서 linear layer 대신 convolution layer을 사용하는 구조이다. 기본적으로 latent variable은 벡터 구조이기 때문에 인코더의 아웃풋 피쳐맵을 flatten해서 hidden layer를 통과시키고 그 결과를 다시 피쳐맵으로 만들어 디코더를 통과시킨다.
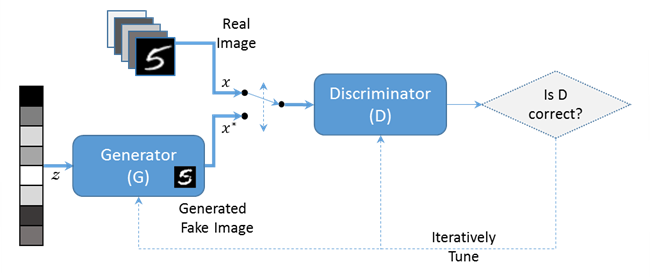
GAN(Generative Adversarial Network)
수학적인 원리 더 자세히 이해 필요
Concept
GAN은 Generator(생성기)와 Discriminator(판별기)라는 서로 다른 두개의 네트워크로 이루어져있으며 이를 적대적으로 학습시킨다. 생성 모델의 목적은 진짜 분포에 가까운 가짜 분포를 생성하는 것이고 판별 모델의 목적은 표본이 가짜 분포에 속하는지 진짜 분포에 속하는지 정확히 결정하는 것이다. 이를 통한 GAN의 궁극적인 목적은 판별기가 실제 데이터와 생성한 데이터를 구분하지 못할 만큼 유사한 데이터를 생성하는 것이다.
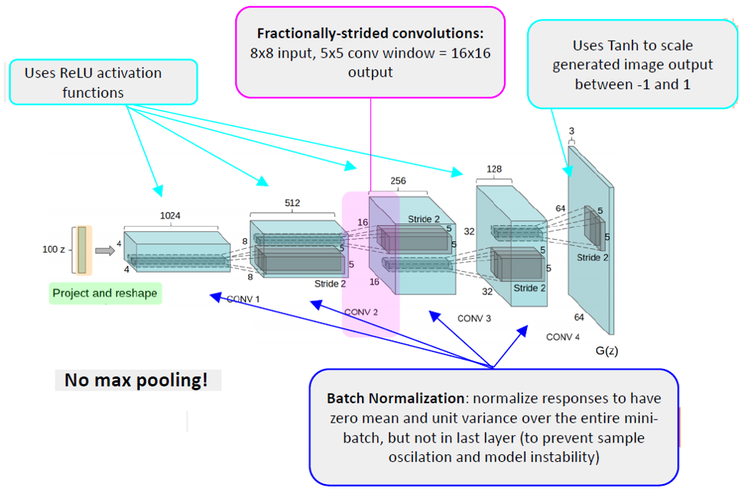
DCGAN(Deep Convolutional Generative Adversarial Network)
기존의 GAN에 Linear layer(다층 퍼셉트론) 대신 Convolution layer를 도입한 모델이다. Vanila GAN 보다 훨씬 좋은 성능을 내며 생성된 이미지를 확인해보면 더욱 선명한 이미지를 생성하는 것을 알 수 있다. DCGAN이 등장한 이후 GAN이 많은 발전을 할 수 있었다.
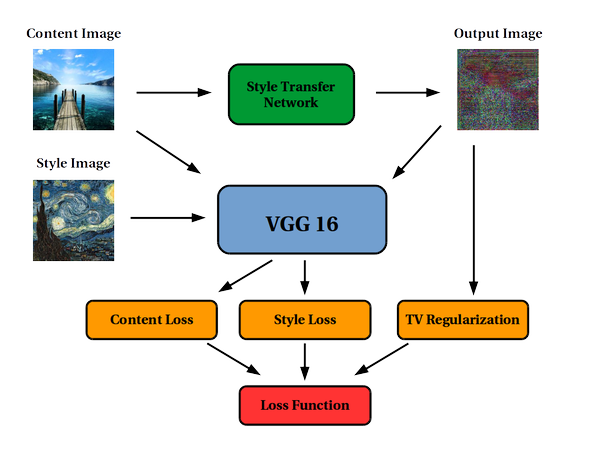
Neural Style Transfer
추가 조사 및 작성 필요
Style Transfer는 앞선 네트워크들과 달리 네트워크를 최적화 하지 않고 생성된 결과 이미지를 최적화 한다. 따라서 Style Extract(context, feature extract)를 위해 pre-trained 된 네트워크를 가져와 사용한다. 논문에서는 VGG 네트워크의 feature map을 이용하여 context image와 style image의 정보를 input image에 줌으로써 학습을 진행하였다.
일반적으로 원본 image의 style로부터 context를 분리하는 것은 매우 어렵지만 Deep Convolutional Neural Network의 도입으로 image의 high-level semantic information을 추출할 수 있기 때문에 style transfer가 가능하다.
Leave a comment